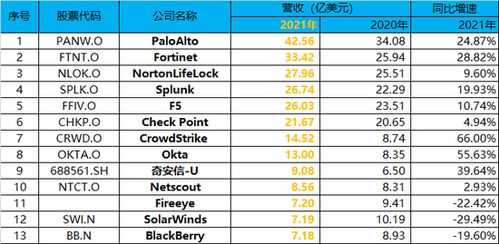
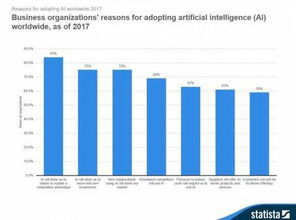
LOF(Local Outlier Factor)算法是一种异常检测算法。它可以通过计算数据点周围的局部密度来判断数据点的异常。本文将从多个方面详细阐述LOF算法的原理和应用。
1。 LOF算法基本思想
LOF算法的基本思想是通过计算一个数据点与其周围邻居的局部密度比来判断异常程度。具体来说,对于一个数据点,如果其周围邻居的密度比值较小,则说明该数据点距离其他数据点较远,可能是异常值;反之,如果密度比大,则意味着该数据点与其他数据点更接近,可能是正常点。
2。 LOF算法计算步骤
将 numpy 导入为 np
从 sklearn.neighbors 导入 NearestNeighbors
def local_outlier_factor(X, k):
nbrs = 最近邻居(n_neighbors=k).fit(X)
距离,索引 = nbrs.kneighbors(X)
lrd = local_reachability_密度(X,k,距离)
lof = np.zeros_like(lrd)
对于范围内的 i(X.shape[0]):
lrd_ratios = lrd[索引[i]] / lrd[i]
lof[i] = np.mean(lrd_ratios)
返回洛夫
def local_reachability_密度(X, k, 距离):
lrd = np.zeros(X.shape[0])
对于范围内的 i(X.shape[0]):
k_距离 = 距离[i, -1]
如果 k_距离 == 0:
可达性距离 = 0
别的:reachability_dist = k / (np.sum(距离[i, :k]) / k_distance)
lrd[i] = 1 /reachability_dist
返回主键
# 样本数据
X = np.array([[1, 2], [2, 3], [3, 4], [10, 20]])
lof = local_outlier_factor(X, k=3)
打印(lof)
3。 LOF算法讲解
LOF 算法通过计算数据点与其周围邻居的局部密度比来确定异常程度。局部密度是通过LOF算法中的“局部可达性密度”(LRD)来计算的。 LRD 测量数据点与其 k 个最近邻点之间的平均密度。密度越高,数据点与其他数据点越接近。然后,通过计算该数据点的LRD与其邻居的LRD的比率来获得该数据点的LOF值。 LOF越大,数据点越异常。
1。异常检测
LOF算法广泛应用于异常检测领域。通过计算数据点的LOF值,可以快速识别不符合正常模式的数据点,例如金融欺诈、网络入侵等异常行为。实际应用中,可以根据LOF值的大小设置阈值,将LOF值超过阈值的数据点识别为异常。
2。聚类分析
LOF算法也可以用于聚类分析。通过计算数据点的LOF值,可以对数据点进行聚类和分类。一般来说,LOF值较小的数据点属于紧密簇,而LOF值较大的数据点则代表离散点或异常值。
3。数据可视化
LOF算法也可用于数据可视化。通过计算数据点的LOF值,可以对数据点进行着色和区分。 LOF值较小的数据点可以用一种颜色着色,LOF值较大的数据点可以用另一种颜色着色,从而直观地展示数据点的异常程度。
本文详细介绍了LOF算法的原理和应用。 LOF算法通过计算数据点与其周围邻居的局部密度比来确定数据点的异常。广泛应用于异常检测、聚类分析、数据可视化等领域。通过理解和应用LOF算法,我们可以更好地处理和分析各类异常数据。