说到 Transf 或mer,你可能会想到 BERT[1]、GPT-3[2] 等,它们都是使用无监督训练的大规模预训练模型。既然Transformer也可以用在CV上,那么它能做类似的事情吗?本文使用ImageNet训练一个图像预训练模型(IPT),可以实现降噪、超分辨率和去雨功能。
动力tivation
目前很多底层任务其实都是有一定程度关联的,即对一项底层任务的预训练对另一项任务有帮助,但目前几乎没有人在做相关的工作。此外,对于某些数据稀缺的任务,预训练是必要的,无论是在 CV 还是 NLP 中,使用预训练模型都是很常见的。对于一些输入和输出都是图像的低级算法,当前的预训练模型显然不适合。
准备数据集
因为Transformer需要大量的数据来拟合,所以必须使用大的数据集。在本文中,作者使用了imagenet。对于 imagenet 中的每个图像,都会生成对应于各种任务的图像对。例如,对于超分辨率,模型的输入数据是imagenet的下采样数据,标签是原始图片。
IPT
正如上一篇文章中介绍的,由于Transformer本身是在NLP领域使用的,所以输入应该是一个序列,所以本文的做法与ViT[3]相同。首先,需要将特征图分成块,并且每个块被认为是一个单词。但不同的是,由于IPT同时训练多个任务,因此模型定义了对应不同任务的多个head和tail。
整个模型架构由四部分组成:用于提取特征的heads、Transformer Encoder、Transformer Decoder、以及用于将特征图恢复到输出的tails。
头
不同的头对应不同的任务。由于IPT需要处理多个任务,所以是多头结构。每个头由 3 个卷积层组成。 Heads要完成的任务可以描述为:fH = Hi(x),x是输入图像,f是第i个Head的输出。
变压器编码器
在输入Transformer之前,需要将Head输出的特征图划分为patch。还需要添加位置编码信息。与ViT不同的是,这里直接相加可以作为Transformer Encoder的输入。不需要进行线性投影。
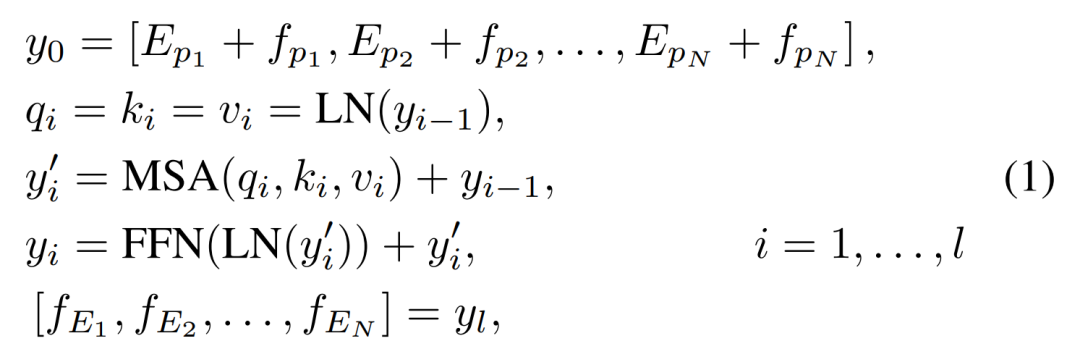
fpi是特征图的一个patch,Epi∈RP*P×C是fpi的可学习位置编码。 LN 是层归一化,MSA 是多头自学习模块,FFN 是前馈网络。
变压器解码器
Transformer解码器的输入是编码器和任务嵌入的输出。这些任务嵌入是可训练的,不同的任务嵌入代表处理不同的任务。解码器的计算可以表示为:
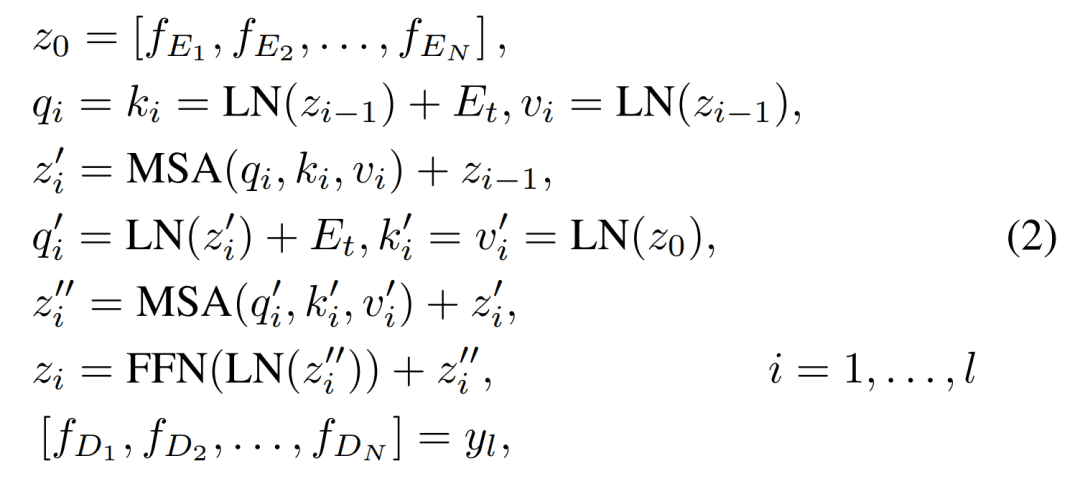
fEi指编码器的输出,fDi指解码器的输出。
尾巴
Tails和Heads是一一对应的,但是不同tails的输出大小可能不同。例如,进行超分时,输出比输入图像大,因此其他尾部的输出大小可能不同。
损失
损失由两部分组成,分别是Lcontrastive和Lsupervised的加权和。
Lsupervised是指IPT输出和标签的L1损失。
添加 Lcontrastive 是为了最小化同一图片的不同 patch 的 Transformer 解码器输出之间的距离,并最大化不同图片的 patch 之间的输出之间的距离。
实验与结果
作者使用了 32 个 NVIDIA Tesla V100,训练了 200 个 epoch,batch size 为 256。
参考
[1]Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 KristinaToutanova。 Bert:用于语言理解的深度双向变换rs的预训练。 arXiv preprintarXiv:1810.04805, 2018.
[2]Tom B Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sas尝试,阿曼达·阿斯克尔等人。语言模型是小样本学习者。 arXiv preprintarXiv:2005.14165, 2020.
[3]Dosovitskiy A、Beyer L、Kolesnikov A 等。一张图像相当于 16x16 个单词:用于大规模图像识别的 Transformer[J]. arXiv 预印本 arXiv:2010.11929, 2020.
责任编辑:lq
-->