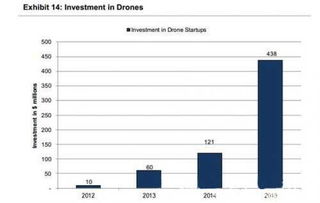
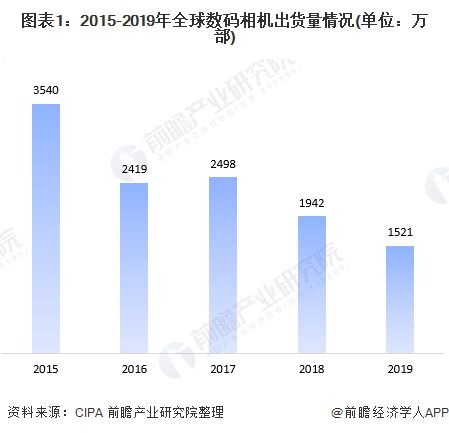
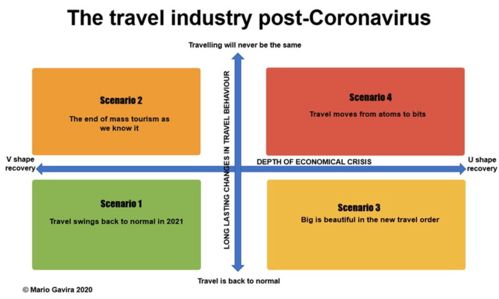
本文将从多个方面详细讲解如何使用Python脚本操作Hive。
使用Python脚本操作Hive之前,首先需要连接并配置Hive。这是示例代码:
从 pyhive 导入配置单元 #创建Hive连接 conn = hive.Connection(主机='', 端口= , 用户名=' ') # 设置默认数据库 conn.cursor().execute("使用 ")
以上代码通过pyhive库提供的Connection类创建Hive连接,并通过execute方法执行Hive USE语句设置默认数据库。
使用Python脚本执行Hive查询是常见的操作之一。以下是执行 Hive 查询的示例代码:
# 执行Hive查询 查询=“从选择*” 光标 = conn.cursor() 光标.执行(查询) # 获取查询结果 结果 = 游标.fetchall()
上面的代码通过execute方法执行Hive查询语句,并通过fetchall方法获取查询结果。
除了执行查询之外,Python脚本还可以用于执行Hive数据加载和导出操作。以下是数据加载和导出的示例代码:
#创建外部表 create_table_query =“创建外部表(col1 INT,col2 STRING)位置' '” 光标.执行(创建表查询) # 下载数据 load_data_query = "将数据输入路径' '加载到表 " 光标.执行(load_data_query) # 导出数据export_data_query = "插入覆盖本地目录 ' ' SELECT * FROM " 光标.执行(导出数据查询)
上面的代码通过execute方法执行Hive语句,实现创建外部表、加载数据、导出数据的操作。
除了使用pyhive库之外,还可以使用其他Python库来操作Hive,例如pyspark和pyarrow。以下是使用pyspark库操作Hive的示例代码:
从 pyspark.sql 导入 SparkSession
# 创建 SparkSession
火花 = SparkSession.builder \
.appName('') \
.config('spark.sql.warehouse.dir', '') \
.enableHiveSupport() \
.getOrCreate()
# 使用 Spark SQL 执行 Hive 查询
查询=“从选择*”
结果=spark.sql(查询)
结果.show()
以上代码通过pyspark库创建SparkSession,通过Spark SQL执行Hive查询,并通过show方法显示查询结果。
本文详细介绍了使用Python脚本操作Hive的几个方面,包括连接和配置、执行查询、数据加载和导出以及使用Python库操作Hive。通过这些示例代码和方法,您可以更方便地使用Python处理Hive数据。