介绍tion
本文提出了Adversarial Self-Attetion机制(ASA),利用对抗性训练来重构Transformer的注意力,使得模型没有在模型结构中受过污染训练。试图解决的问题:
大量证据表明,自注意力可以从允许偏差中受益,这可以在原始注意力结构上添加一定程度的先验(例如掩蔽、分布平滑)。这种先验知识使模型能够从较小的语料库中学习有用的知识。然而,这些先验知识通常是特定于任务的知识,使得模型很难扩展到丰富的任务。
对抗性训练通过向输入内容添加扰动来提高模型的稳健性。作者发现仅仅在输入嵌入中添加扰动很难混淆注意力图。模型的注意力在扰动前后没有变化。
为了解决以上问题,作者提出了ASA,它具有以下优点:
最大化经验训练风险,并在自动构建先验知识的过程中学习有偏见(或对抗性)的结构。
对抗结构是从输入数据中学习的,这使得 ASA 不同于传统的对抗训练或自注意力变体。
使用梯度反转层将模型和对手结合成一个整体。
ASA 自然是可解释的。
初步
代表输入特征。在传统的对抗训练中,它通常是一个令牌序列或令牌的嵌入,它代表了地面事实。对于由参数化的模型,模型的预测结果可以表示为 。
2.1 对抗性训练
对抗训练的目的是通过拉近扰动模型预测与目标分布之间的距离来提高模型的鲁棒性:
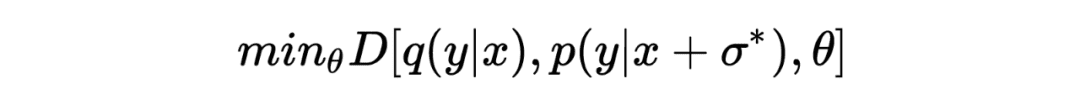
其中 表示对抗性扰动后的模型预测,表示模型的目标分布。通过最大化经验训练风险获得的抗扰动:

其中 是 对 的约束,希望在 较小时对模型造成更大的扰动。以上两种表述展示了对抗的过程。
2.2一般自注意力
定义自注意力的表达式是:

在最常见的自注意力机制中, 代表一个全等矩阵,而在之前的研究中, 代表一定程度的先验知识,用于平滑注意力结构的输出分布。作者在本文中定义为一个二元矩阵,其元素为 。
对抗性自注意力机制
3.1 优化
ASA 的目的是掩盖模型中最脆弱的注意力单元。这些最脆弱的单元取决于模型的输入,因此对抗性可以表示为通过输入学习的“元知识ledge”:ASA注意力可以表示为:

与对抗训练类似,该模型用于最小化以下分歧:

通过最大化经验风险来估计:

其中 代表 的决策边界,用于防止 ASA 损害模型训练。
考虑到以attention mask的形式存在,更适合通过约束masked单元的比例来进行约束。因为它很难衡量。的具体值,因此硬约束转化为无约束并带有惩罚:

其中t用于控制对抗程度。
3.2 实施
作者提出了一种简单而快速的 ASA 实施方案。

对于self-attention层,可以从输入隐藏层状态得到。具体来说,使用线性层将隐藏层状态转换为 和 ,通过点乘得到矩阵,然后通过重参数化技术对矩阵进行二值化。由于对抗性训练通常包括两个目标:内部最大化和外部最小化,因此至少需要两个backward过程。因此,为了加快训练速度,作者使用梯度反转层(GRL)来合并两个过程。
3.3 训练
培训目标如下:

表示特定任务的ic损失,表示添加ASA对抗后的损失,表示 的约束。
实验
4.1结果

从上表可以看出,在微调方面,ASA支持的模型始终在很大程度上超过了原有的BERT和RoBERTa。可以看到,ASA在STS-B、DREAM等小规模数据集上表现良好(一般认为这些小规模数据集更容易过拟合),同时仍然有很好的拟合效果。在MNLI、QNLI和QQP等更大规模数据集上的改进,这表明ASA可以提高模型的泛化能力。模型的语言表示能力。如下表所示,ASA在提高模型稳健性方面发挥着更大的作用。
4.2 分析实验
1.VS。朴素平滑 将 ASA 与其他注意力平滑方法进行比较。

2.VS。对抗性训练 将 ASA 与其他对抗性训练方法进行比较

4.3可视化
1. ASA为何提高泛化能力 对抗可以削弱关键词的注意力,让非关键词受到更多的关注。 ASA 防止模型做出懒惰的预测,但敦促它从受污染的线索中学习,从而提高泛化能力。

2.底层rs比较脆弱。可以看出,随着层数从底部到顶部,掩模的比例逐渐减小。遮蔽比例越高,意味着该层越容易受到攻击。

结论
本文提出对抗性自注意力机制(ASA)来提高预训练语言模型的泛化性和鲁棒性。大量实验表明,本文提出的方法可以提高模型在预训练和微调阶段的鲁棒性。
·审稿人:李谦
-->