华盛顿大学计算机科学系博士生陈天琪与上海交通大学、复旦大学的研究团队提出了一种基于学习的框架,用于优化深度学习工作负载的张量程序。该研究采用基于机器学习的方法来自动优化张量运算核心并编译AI工作负载,从而将最佳性能部署到所有硬件。实验结果表明,该框架能够提供与低功耗 CPU、移动 GPU 和服务器级 GPU 的最先进的手动调整库相当的性能。
深度学习在我们的日常生活中已经无处不在。深度学习模型现在可以识别图像、理解自然语言、玩游戏以及自动执行系统决策(例如设备放置和索引)。张量算子(tens或算子),例如矩阵乘法和高维卷积,是深度学习模型的基本组成部分。
可扩展的学习系统依赖于手动优化的高性能张量操作库,例如 cuDNN。这些库针对较小范围的硬件进行了优化。为了优化张量运算符,程序员需要从逻辑上等效但由于线程、内存重用、pipelined和其他硬件因素而有所不同的实现中进行选择。性能差异巨大。
支持多个硬件后端需要巨大的工程工作。即使在目前支持的硬件上,深度学习框架和模型的开发也从根本上受到库中优化算子设置的限制,无法进行算子融合等优化,导致算子不受支持。
针对这一问题,华盛顿大学计算机系博士生陈天奇与上海交通大学、复旦大学的研究团队提出了一种基于学习的框架来优化深度学习工作负载的张量程序(张量程序rams)。

总结
我们提出了一个基于学习的框架来优化深度学习工作负载的张量程序。矩阵乘法和高维卷积等张量算子的高效实现是有效深度学习系统的关键。然而,现有系统依赖于手动优化的库(例如 cuDNN),而很少有服务器级 GPU 能够很好地支持这些库。对硬件要求较高的操作库的依赖限制了高级图形优化的适用性,并且在部署到新的硬件目标时会产生大量的工程成本。我们利用学习来消除这种工程负担。我们学习特定领域的统计成本模型,以指导在数十亿可能的程序变体中搜索张量运算符的实现。我们通过跨工作负载的高效模型迁移进一步加快搜索速度。
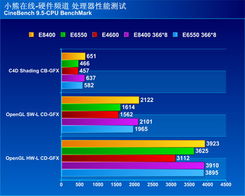
实验结果表明,我们的框架能够提供与低功耗 CPU、移动 GPU 和服务器级 GPU 的最先进的手动调整库相当的性能。
学习优化张量规划问题的形式化方法
我们提出以下问题:我们能否通过学习来减轻这种工程负担,并针对给定的硬件平台自动优化张量算子程序?本文对这个问题给出了肯定的答案。我们构建统计成本模型来预测给定低级程序的程序运行时间。这些成本模型指导对可能程序空间的探索。我们的成本模型使用可转移的表示形式,可以跨不同的工作负载进行泛化,以加快搜索速度。这项工作的贡献如下:
我们提供了一种正式的方法来解决学习优化张量程序的问题并总结其关键特征。
我们提出了一个基于机器学习的框架来解决这个新问题。
我们使用迁移学习将优化速度进一步提高 2 倍到 10 倍。
我们在此框架中提供详细的组件设计选择和实证分析。

真实深度学习工作负载的实验结果表明,我们的框架提供了比现有框架高 1.2 倍到 3.8 倍的端到端性能改进。

图 1:此问题的示例。对于给定的张量运算符规范,有多种可能的低级程序实现,每种实现都有不同的循环顺序、tiling 大小和其他选项。每个选项都会创建一个具有不同功能的逻辑上等效的程序。我们的问题是探索程序空间并找到优化的程序。

图2:学习优化张量程序框架概述

学习优化张量程序算法

图 3:编码低级循环 AST 的可能方法示例

表 1:单批 ResNet-18 推理中所有 conv2d 运算符的配置。 H、W 表示高度和宽度,IC 表示输入通道,OC 表示输出通道,K 表示内核大小,S 表示步幅大小。
讨论与结论
我们提出了一种基于机器学习的框架来自动优化深度学习系统中张量算子的实现。我们的统计成本模型允许在工作负载之间高效共享模型,并通过模型迁移加速优化过程。这种新方法的出色实验结果显示了深度学习部署的好处。
除了我们的解决方案框架之外,这个新问题的具体特征使其成为相关领域创新的理想测试平台,例如神经程序建模、贝叶斯优化、迁移学习和强化学习。
在系统方面,学习优化张量程序可以实现跨不同硬件后端的更多融合算子、数据布局和数据类型。这些改进对于改进深度学习系统至关重要。我们将开放我们的实验框架,以鼓励在这些方向上进行更多研究。
-->